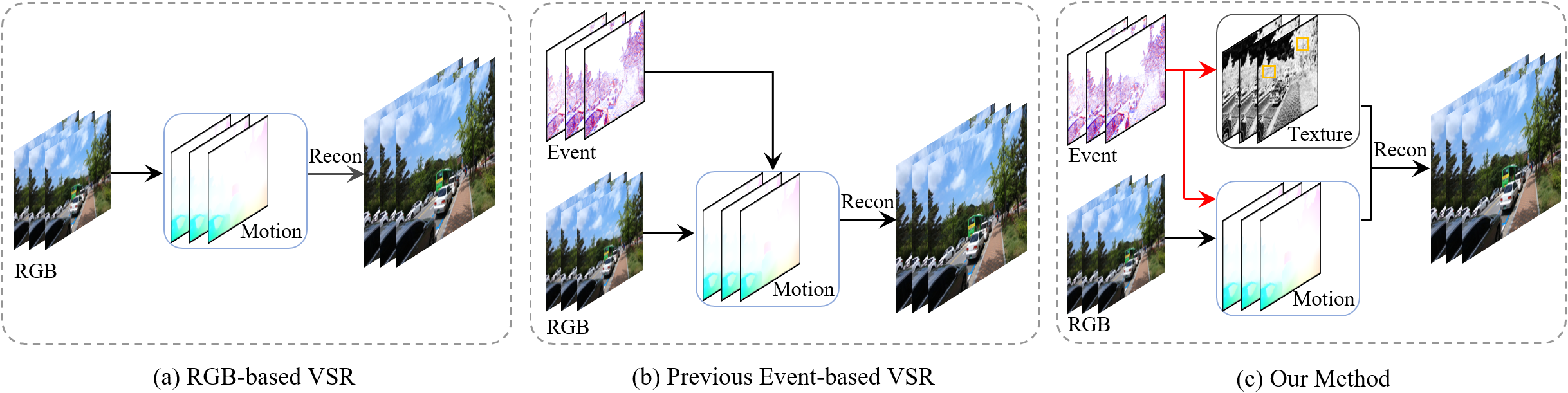
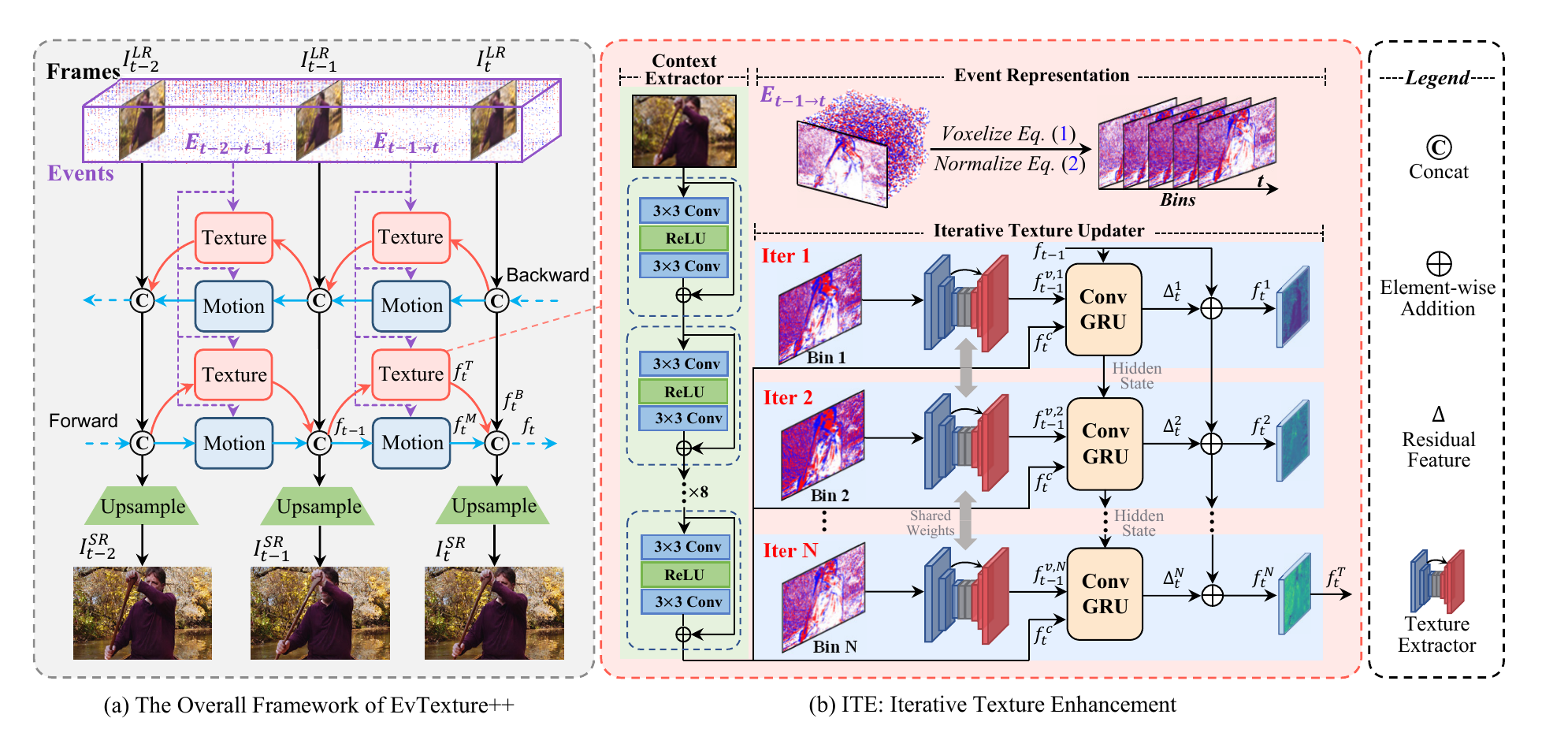
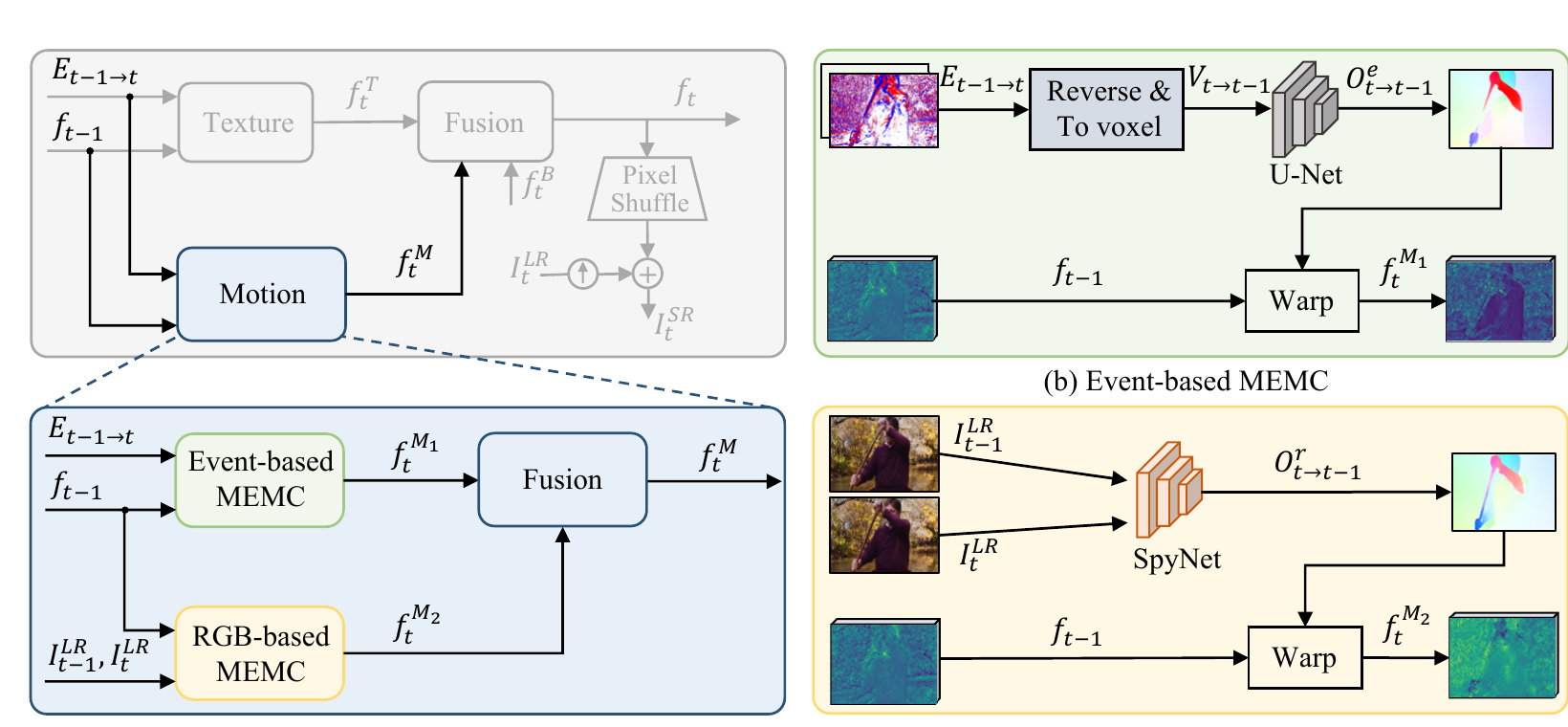
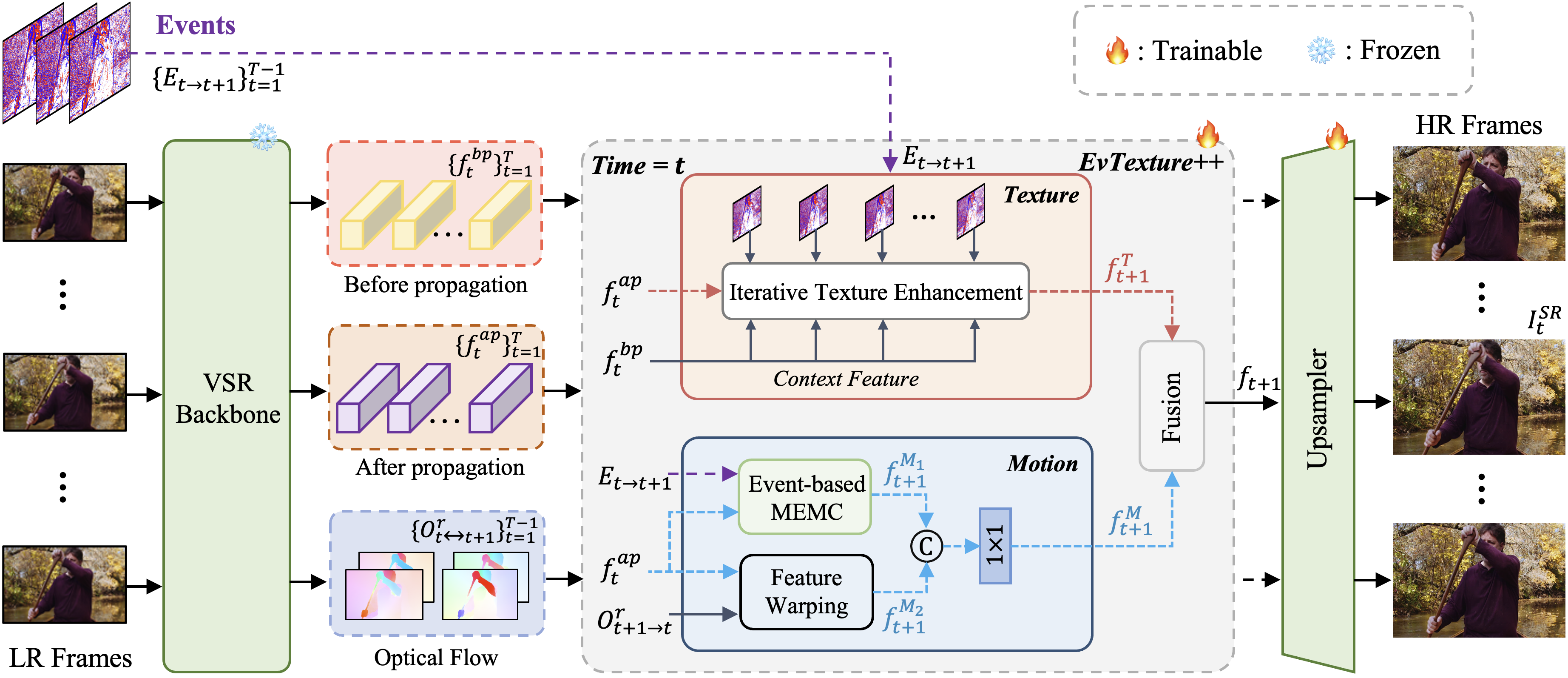
Motivation

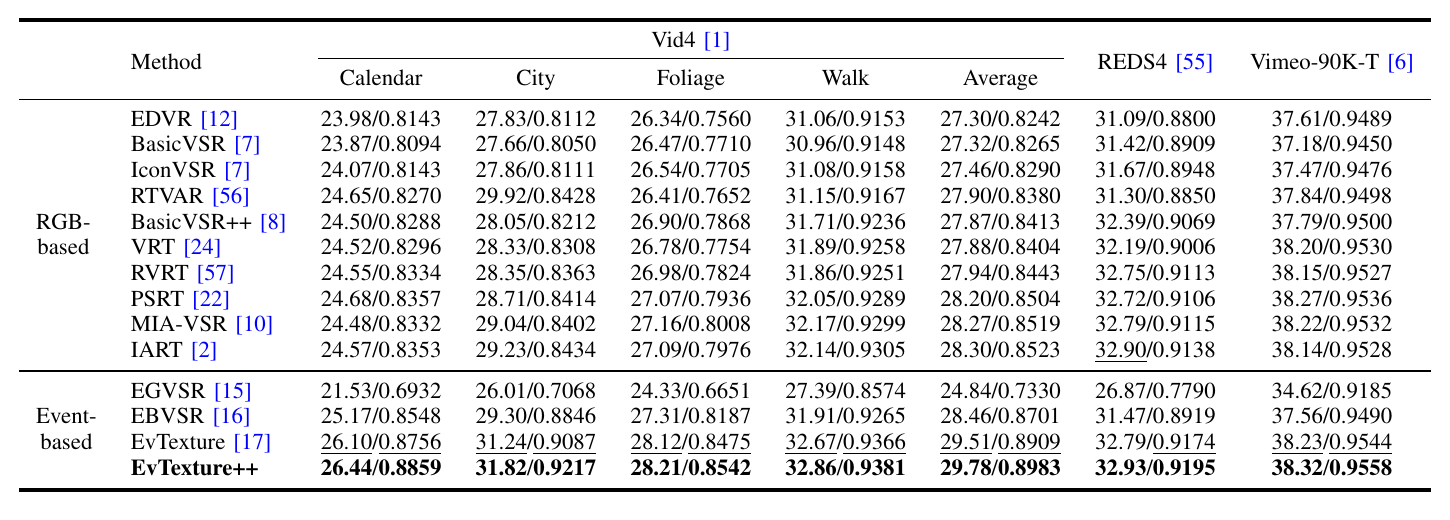
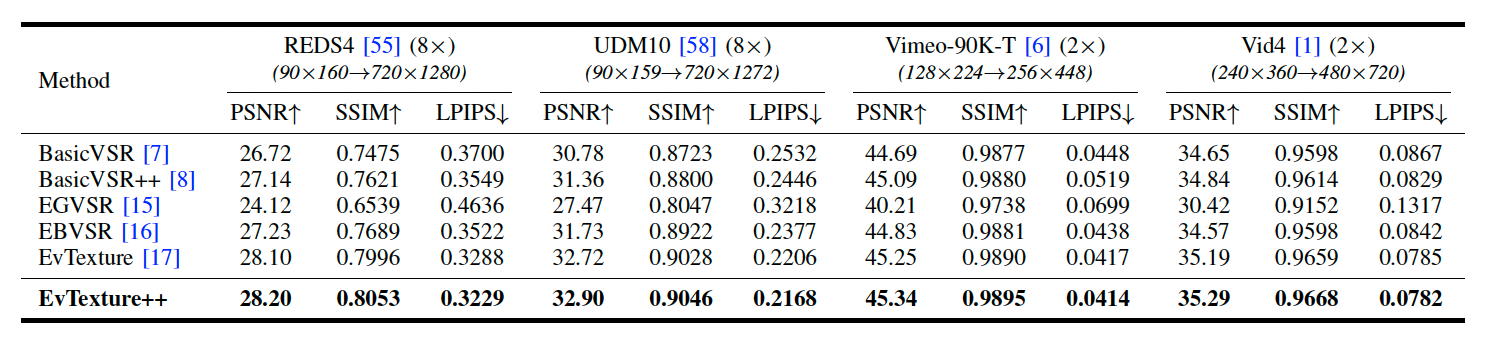
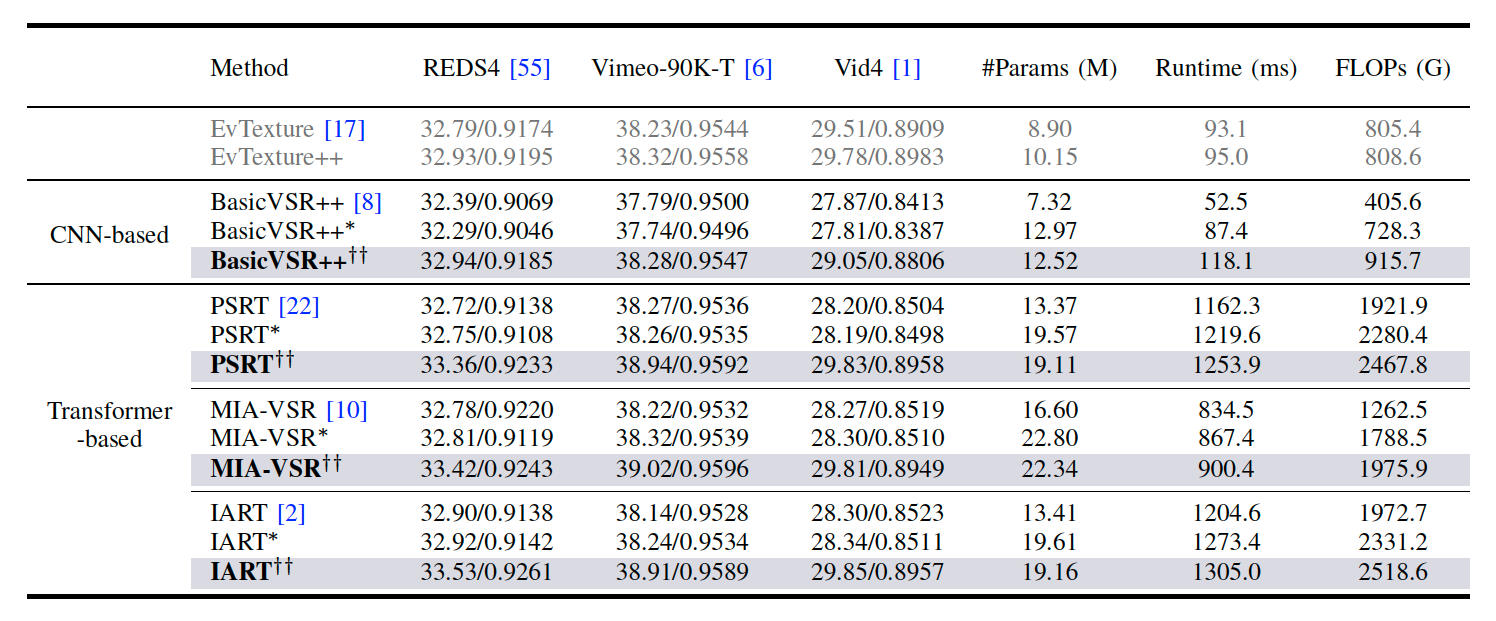
Visual comparison on a challenging texture-rich scene. While current VSR methods, whether frame-based (e.g., MIA-VSR and IART) or event-based (e.g., EGVSR), suffer from severe over-smoothing, our EvTexture++ successfully reconstructs coherent building stripes. This is further validated by the error maps, where our method exhibits significantly lower residuals by leveraging high-frequency event information.